Case omschrijving
Voor een klant heb ik een Proof of Concept gemaakt om grote hoeveelheden XML bestanden te transformeren het gaat dan 3000 bestanden per keer met een totale grote van 18 gigabyte. Voor dit artikel kan ik wegens privacy niet de echte data gebruiken en heb ik een dataset gebruikt van https://www.kaggle.com/datasets het gaat hier om een dataset met landen en de wijnen welke uit het desbetreffende land komen.
Het doel is om de wijnen uit de XML dump te halen en deze om te zetten naar een JSON formaat en deze bestanden te uploaden in een blob container. We krijgen dus per wijn een JSON bestand in een blob container. Dit alles moet gebeuren op basis van durable functions en een constumption plan.
Wat is de opzet van de POC
Ik ga hier niet heel diep in op wat Durable functions zijn want dat heeft Microsoft heel goed omschreven in hun documentatie https://docs.microsoft.com/en-us/azure/azure-functions/durable/durable-functions-overview.
Ik heb 40 bestanden met landen en wijnen. 1 bestand is ongeveer 75 mb groot. Voor test doeleinde zijn dit dezelfde bestanden met een andere naam. Dit is meer om een gelijkwaardige load op de functie te krijgen als bij de echte POC.
Ik maak in de POC gebruik ik een extract countries activity om de landen uit de XML te halen. Hierna ga met het fan out principe ik per land een activity starten om de wijnen per land uit structuur te halen. Als dit allemaal klaar is wordt er per wijn een activity gestart welke de wijn in JSON formaat upload in een blob container.
Zie hier een overzicht van de durable function: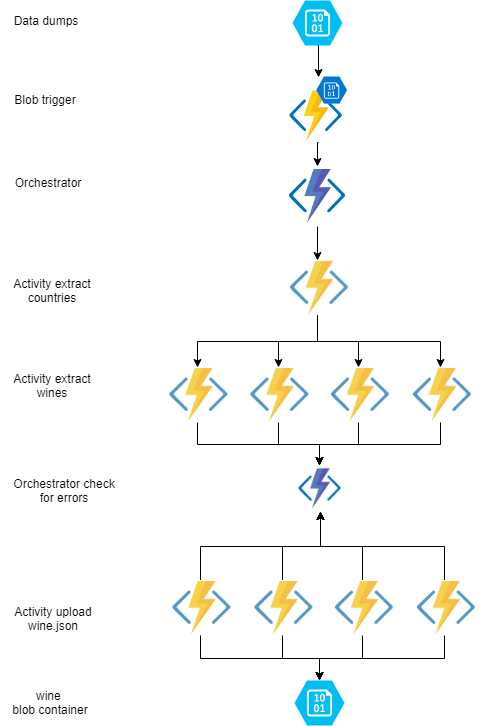
Waar ben ik tegenaan gelopen tijdens de POC
Op papier leek dit de meest perfecte oplossing ik kon de landen in een activity uit de dump halen en dan per land een activity starten om de wijnen op te halen.
Dit geeft je een goede schaalbaarheid, als er meer landen in komen worden er meer extract wine activitiy taken aangemaakt.
Als er meer wijnen per land komen worden er meerdere upload activity taken aangemaakt.
Per bestand gaat de blob trigger af op de functie. De blob triggers welke niet meteen afgehandeld kunnen worden worden in een queue opgeslagen in het storage account van de function. Deze queue heeft een naam welke begint met azure-webjobs-blobtrigger-
Als het bestand binnenkomt wordt er een orchestrator opgestart welke de blobnaam doorgeeft aan de orchestrator.1
2
3
4
5
6
7
8
9
10[]
public static async Task Run(
[BlobTrigger("wine/{name}")]Stream myBlob,
string name,
[OrchestrationClient]DurableOrchestrationClient starter,
ILogger log)
{
log.LogDebug($"Process file: {name}");
await starter.StartNewAsync("O_Orchestrator", name);
}
De orchestrator start de activity A_ExtractWineCountries op om de XML op land niveau op te knippen en wacht tot dit klaar is.1
2
3
4
5
6[]
public static async Task Orchestrator([OrchestrationTrigger] DurableOrchestrationContext context, ILogger log)
{
var fileName = context.GetInput<string>();
var wineData = await context.CallActivityAsync<Countries[]>("A_ExtractWineCountries", fileName);
}
Als dit klaar is wordt er per land de activity A_ExtractWines gestart om de wijnen uit de data te halen.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[]
public static async Task Orchestrator([OrchestrationTrigger] DurableOrchestrationContext context, ILogger log)
{
var fileName = context.GetInput<string>();
var wineCountries = await context.CallActivityAsync<Countries[]>("A_ExtractWineCountries", fileName);
var tasks = new List<Task<Wine[]>>();
foreach (Countries wineCountry in wineCountries)
{
tasks.Add(context.CallActivityAsync<Wine[]>("A_ExtractWines", wineCountry));
}
var wineTasks = await Task.WhenAll(tasks);
}
Als alle wijn data is opgehaald worden deze parallel geupload in de A_UploadWine activity.
1 | [] |
Tot zover ziet het er goed en schaalbaar uit tot ik het publiceerde naar een Azure function app.
Ik kopieer met azcopy 40 bestanden van 75 mb in de blob container wine en start application insights op om te zien hoe de applicatie zich gedraagt.1
AzCopy /Source:https://sourceaccount.blob.core.windows.net/source /Dest:https://destaccount.blob.core.windows.net/wine /SourceKey:key1 /DestKey:key2 /S
Het resultaat wat ik te zien kreeg maakte me alles behalve blij. De applicatie liep niet soepel en stopte soms geheel met het verwerken van bestanden.
Na lang zoeken en fine tunen kwam ik erachter wat een grote oorzaak van het probleem was.
Een Azure function app op een consumption plan heeft een geheugen limiet van 1,5 gigabyte en 1 processor core. Standaard draait Azure durable functions 10X het aantal activities als de host proecessor cores heeft (bij een consumption plan is dit dus 10 activities) en als er toevallig meerdere activities A_ExtractWineCountries worden gestart worden er meerdere XML bestanden in het geheugen geladen a 75 mb. Reken hierbij nog de orchestrator bij en het overige geheugen verbruik van een function app en je zit al snel aan 1,5 gig geheugen.
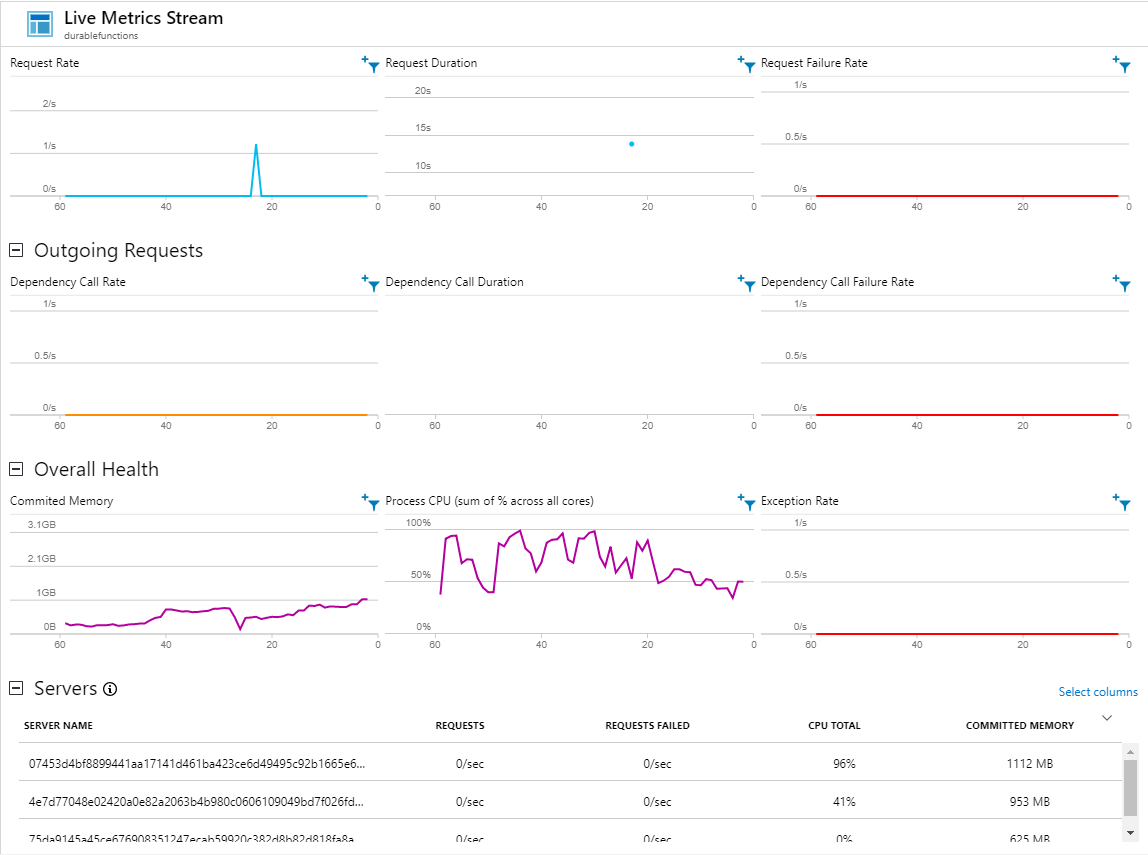
Zie het geheugen verbruik van 1 server zit al op 1112MB deze server.
Als je de geheugen limiet hebt bereikt wordt de server gestopt en worden de taken welke op de function app draaide niet afgemaakt deze worden deze opnieuw gestart op een andere function app.
Je kan instellen hoeveel activities en orchestrators er op een function app gestart mogen worden. Dit kun je doen in de host.config (https://docs.microsoft.com/en-us/azure/azure-functions/durable/durable-functions-bindings#hostjson-settings). Je kan de waardes aanpassen naar een lagere waarde alleen loopt het proces niet lekker stabiel door. Doordat het niet lekker stabiel doorloopt en dit als gevolg heeft dat de cpu belasting op en neer gaat gaat het automatisch schalen niet soepel.1
2
3
4
5
6
7
8{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Demoproject
Ik heb een demo project gemaakt welke een volledig werkende solution bevat.
Zie hieronder de stappen om het durable functions project te starten:
- Clone de repository https://github.com/marcoippel/durablefunctionsdemo
- Maak een storage account aan in Azure
- Maak een functions app aan in Azure en configureer de connectionstring in de appsettings
- Maak in de blob storage een 3 tal blob containers aan genaamd:
- source
- wines
- wine
- Publiseer het project naar de functions app.
- Maak van het bestand DurableFunctionDemo/winedata.xml 40 kopieën en upload deze naar de wine folder in Azure storage
Start applications insight en kijk hoe de applicatie zich gedraagt.
Conclusie
Durable functions op een consumption plan is een hele mooie oplossing maar niet voor een applicatie welke intensief geheugen gebruikt en snel veel bestanden moet verwerken. Je blijft met het geheugen limiet van 1,5 gigabyte en je hebt geen invloed op welke activities er op een functions app worden gehost.
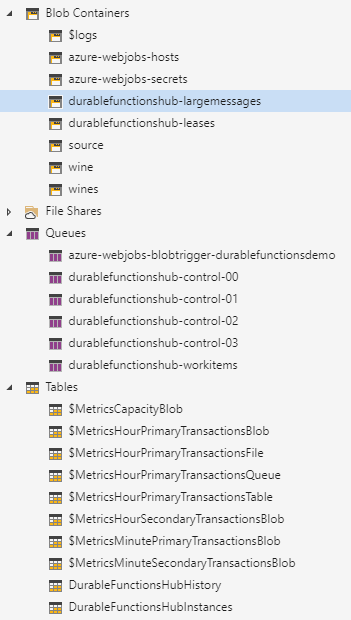
Er zit best wel wat overhead in het proces hij gebruikt namelijk je Azure storage account als queue voor communicatie tussen de orchestrator en de activities. Als je bericht groter is dan in de queue pas plaatst hij het in een blob container. Bijvoorbeeld als de berichten welke naar de activity A_UploadWine gaan groter zijn als 64KB (https://docs.microsoft.com/nl-nl/azure/service-bus-messaging/service-bus-azure-and-service-bus-queues-compared-contrasted#capacity-and-quotas) dan zullen deze in een blob container durablefunctionshub-largemessages worden opgeslagen om vervolgens op gehaald te worden in de activity A_UploadWine en deze activity upload hem dan naar de uiteindelijke blob container. Hier zitten al 2 blob storage acties in welke ook tijd en resources kosten.
Deze POC heeft het doel niet behaald wat we voor ogen hadden en we zullen opzoek gaan naar een andere oplossing. Het idee is om de taken te verdelen over meerdere Azure function apps. Zodra die POC is uitgewerkt zal ik de bevindingen delen in een nieuwe blog.